
This is part 5 of many in my “Open-source as a project model for internal work” series and the final part of “Empathetic Infrastructure Code Management”.
Versions are useful for a quickly gathering how intensive an upgrade will be. The Node Stability Index provides a simple overview of a component's likelihood to change. But sometimes you just need to dig in to the details.
Changelogs fill in those facts. They're files containing a curated, chronologically ordered list of notable changes for each version of project.
That's a long-winded way of saying: "It's a log of changes".
They usually aren't needed unless a version upgrade goes awry, then you're super grateful to have it. They contain all those minute details that can be the difference between figuring something out in five minutes or in five hours.
Why the alternatives don't work
The following are three examples of why I think traditional change status communication stinks. While I made them all up, stories like these occur all too often in our world. Sadly, we settle for this type of communication because it's the way it's always been done.
Story #1: Status meetings suck and people suck at remembering details
It's 9am Monday morning; you're groggy from having woken up only an hour ago and the meeting room is frigid. You forgot to fill up on your caffeinated beverage of choice and you're feeling quite grumpy for it.
You'd rather be at home resting in your warm bed, but you're here because a project manager set up a recurring status update meeting to talk about the latest and greatest with the infrastructure codebase. You have to attend because you're a key stakeholder in the codebase and there's no other way to get the information.
Except you're not really getting the information. Words are being said, someone is presenting on something, but your mind is in no state to focus. You know you're missing some vital information, bet you're not sure what.
The project you're helping lead isn't fully defined, so you're not sure which parts of all of this you'll actually need. You could jot down notes to everything, but again, the lack of coffee is making everything a struggle. You have a sneaking suspicion in two weeks time you'll regret not having paid better attention.
Story #2: Emails turn in to spam and get lost
"Hey, do you remember seeing an email with status updates that came through last week?"
"Yeah, what about it?"
"I'm trying to search for it but can't seem to find it. I've tried looking for 'status update', 'project status', 'weekly roundup'. All of these are returning nothing. Any idea where I can find it?"
"No... I remember they like to get creative with their release names and usually title the email after that. Just email the PM and ask to have another copy of the email sent over."
"Yeah, I guess. Wonder when they'll get tired of me always e-mailing for information they've already sent..."
Story #3: Wiki's hide information because people have to know about them
The demo is tomorrow and I'm stuck searching this codebase for any sort of documentation on the recent changes.
I have the commit log, but it's pretty sparse on details. I can figure out what component was changed, but there are a ton of diffs between these two versions.
I don't understand why our infrastructure doesn't have better docs. Certainly there's something out there. I've got to be missing some detail.
"Hey Julie, do you know where I can find any sort of information on the recent infrastructure update?"
"Yeah, it's on the wiki."
"There's a wiki?!?"
Avoiding knowledge debt
In the three scenarios above, all three sources of status documentation failed on one fact: It relied on humans to store knowledge.
Human's are pretty bad at storing knowledge. Especially long term and especially in a hectic, busy environment. Think of all the data human brains have to process in any 40 hour work week.
This is why written, easy-to-find documentation is so important. You wouldn't hide your component docs in emails, so why do that with your version change history information?
Make it easy for users and contributors to see what notable changes have been made between each release (or version) of the project. Store that data in the code repository itself (in a CHANGELOG.md file in the root of the project directory). This allows the details to be front and center, instead of hidden away in an inbox or wiki that everyone forgets about.
Auto-generating changelogs
Let's be honest, humans are not only bad at remembering details, but they're also pretty lazy at writing the details they do remember down. Make it easier by automating your changelog generation.
Instead of waiting until a release to recall all the details of the changes, record them as you go through a tool you're probably already using: Git.
If you put in a little extra effort in your git commit messages, you can easily auto-generate changelogs from them. A side benefit of this is it encourages useful commit messages (since they’re needed for the changelog).
Angular.js has an interesting approach to formatting their messages. They follow this model:
changeType(componentChanged): Description
Where changeType can be ‘style’, ‘tests’, ‘fix’, etc. Here's a real-world example:
fix(travis): Don't fail the build for screenshots
At release time, these commit messages are parsed and the details are added to the existing changelog file in the repo.
Here's output from an actual generated changelog:
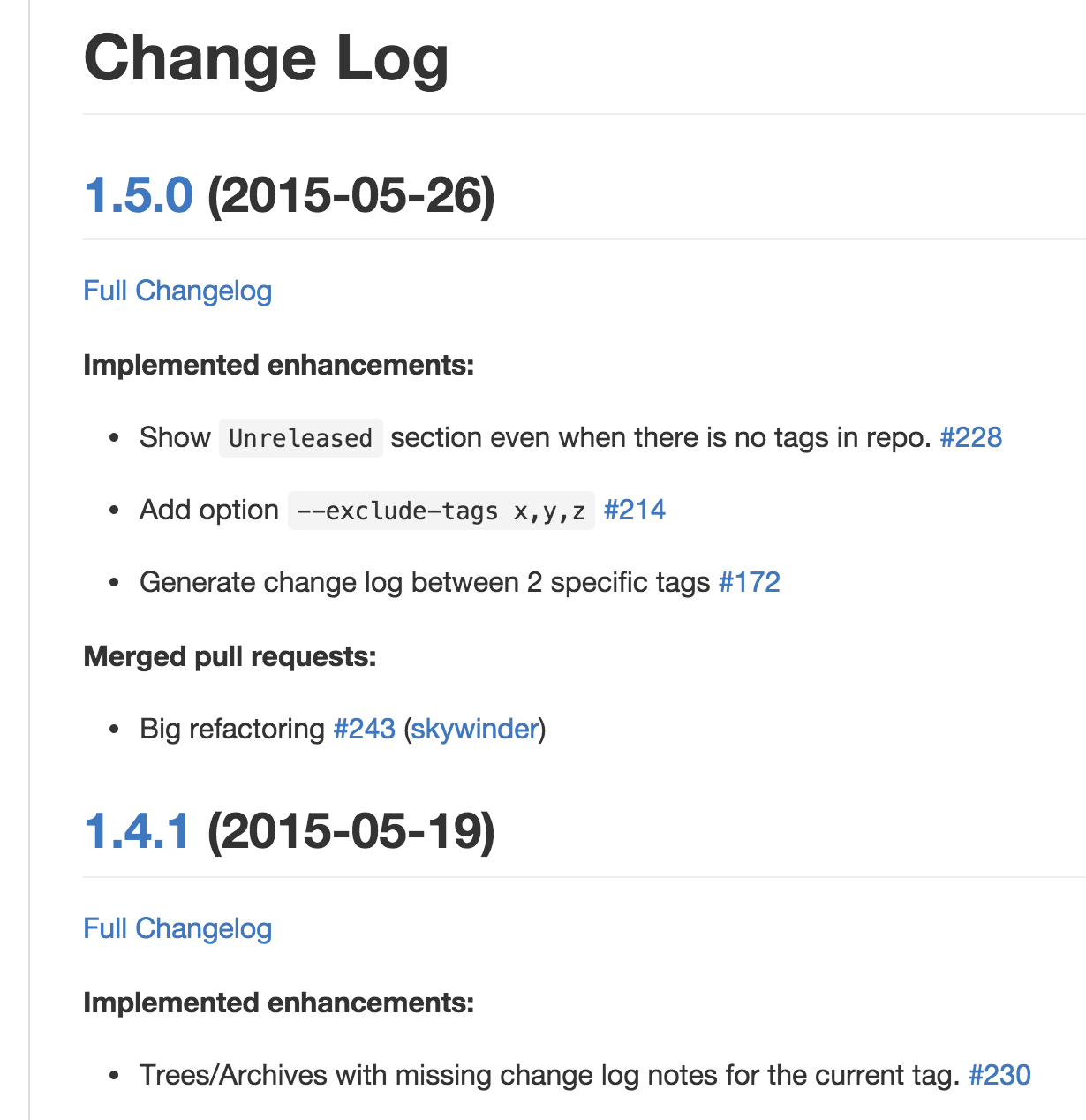
Two tools to help with this are:
Further Reading
keepachangelog.com/ has great details on why changelog's are important and how the industry has been adopting them. I highly encourage scanning their site for more info.
Interested in more? Subscribe to the newsletter to receive updates when a new part in this series is published and for other related information.